Validation of the Dual Tuning & Domain-level Comparison
Table 1: Results of preliminary experiments on spatial reasoning. Baseline: Qwen2.5-VL-7B. I: Image Spatial Data. V: Video Spatial Data. S: Direct-Answer. L: CoT.
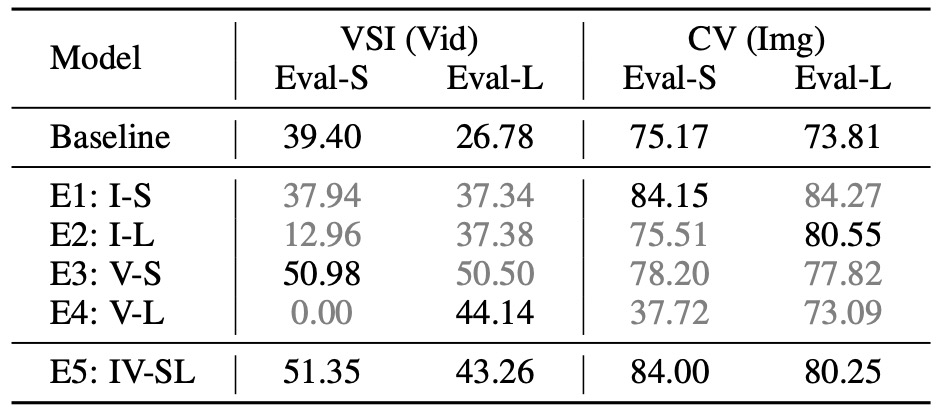
- ✅ For Spatial Benchmarks, Dual Tuning recovers the optimal results of each single-mode training. CoT training shows lower average scores compared to DA training.
Table 2: Results of preliminary experiments on disciplinary reasoning. Baseline: Qwen2.5-VL-7B. O: Onethinker Image Data. S: Direct-Answer. L: CoT.
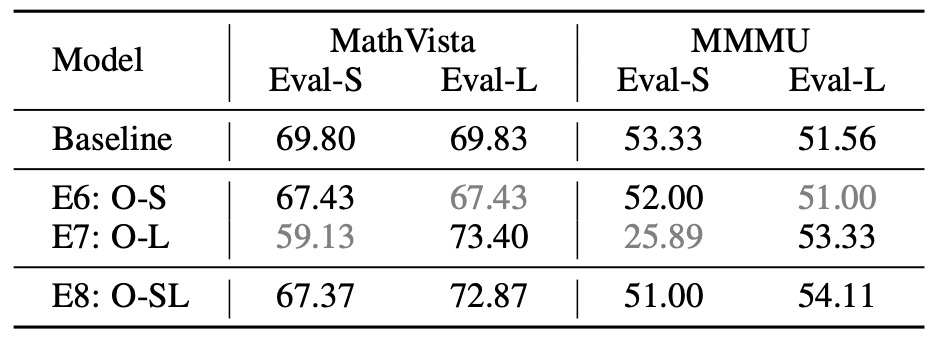
- ✅ For Math and Multi-disciplinary Benchmarks, Dual Tuning recovers the optimal results of each single-mode training. CoT training shows higher average scores compared to DA training.
Fine-Grained Task Analysis
Table 3: Experimental results on spatial tasks. Values in red and green denote negative and positive results, respectively. A task is identified as suitable for reasoning-oriented training only when both \( \mathbf{Gain_{CoT}} \) and \( \mathbf{GAP_{DT}} \) exhibit concurrent positive values (highlighted in green), which constitutes the Thinking Boundary.
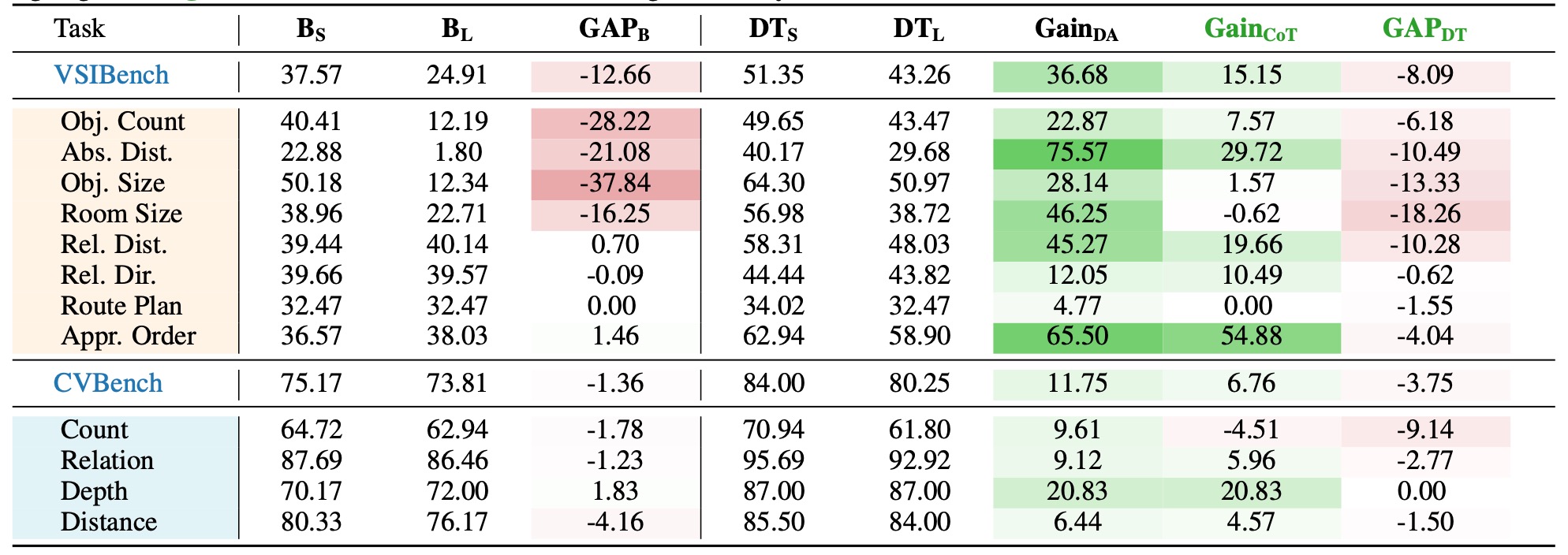
- ✅ Base model: Direct answering outperforms CoT on perception-oriented tasks.
- ✅ Training gains: Both CoT and DA have positive gains, but CoT gains are substantially lower than DA.
Table 4: Experimental results on MathVista tasks. Values in red and green denote negative and positive results, respectively. A task is identified as suitable for reasoning-oriented training only when both \( \mathbf{Gain_{CoT}} \) and \( \mathbf{GAP_{DT}} \) exhibit concurrent positive values (highlighted in green), which constitutes the Thinking Boundary.
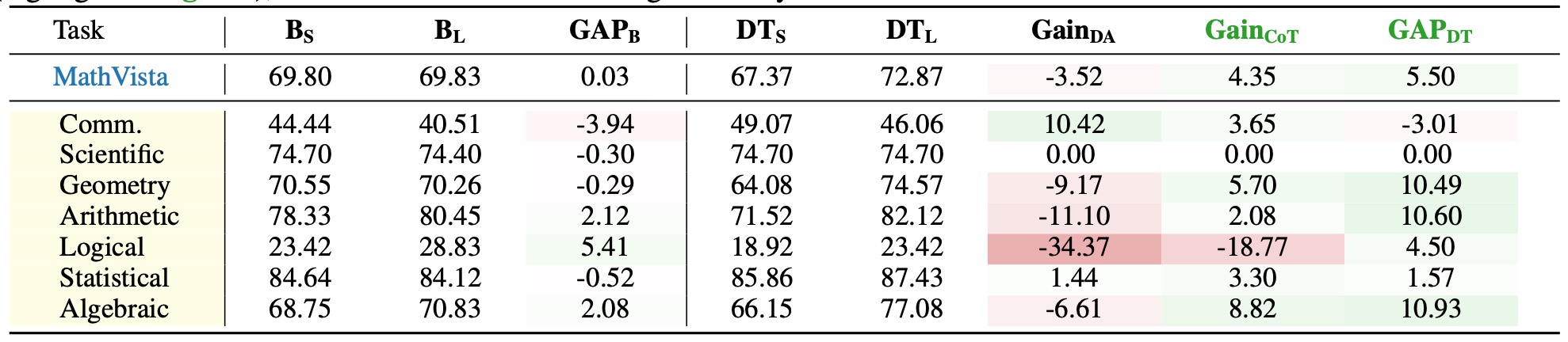
- ✅ Base model: Initial capabilities are comparable between reasoning and non-reasoning inference.
- ✅ Training gains: The majority of fine-grained mathematical tasks show positive Gain from CoT and negative Gain from DA, indicating these tasks benefit more from reasoning training, Numeric Commonsense is the sole exception where CoT underperforms direct answering.
Table 5: Experimental results on MMMU tasks. Values in red and green denote negative and positive results, respectively. A task is identified as suitable for reasoning-oriented training only when both \( \mathbf{Gain_{CoT}} \) and \( \mathbf{GAP_{DT}} \) exhibit concurrent positive values (highlighted in green), which constitutes the Thinking Boundary.
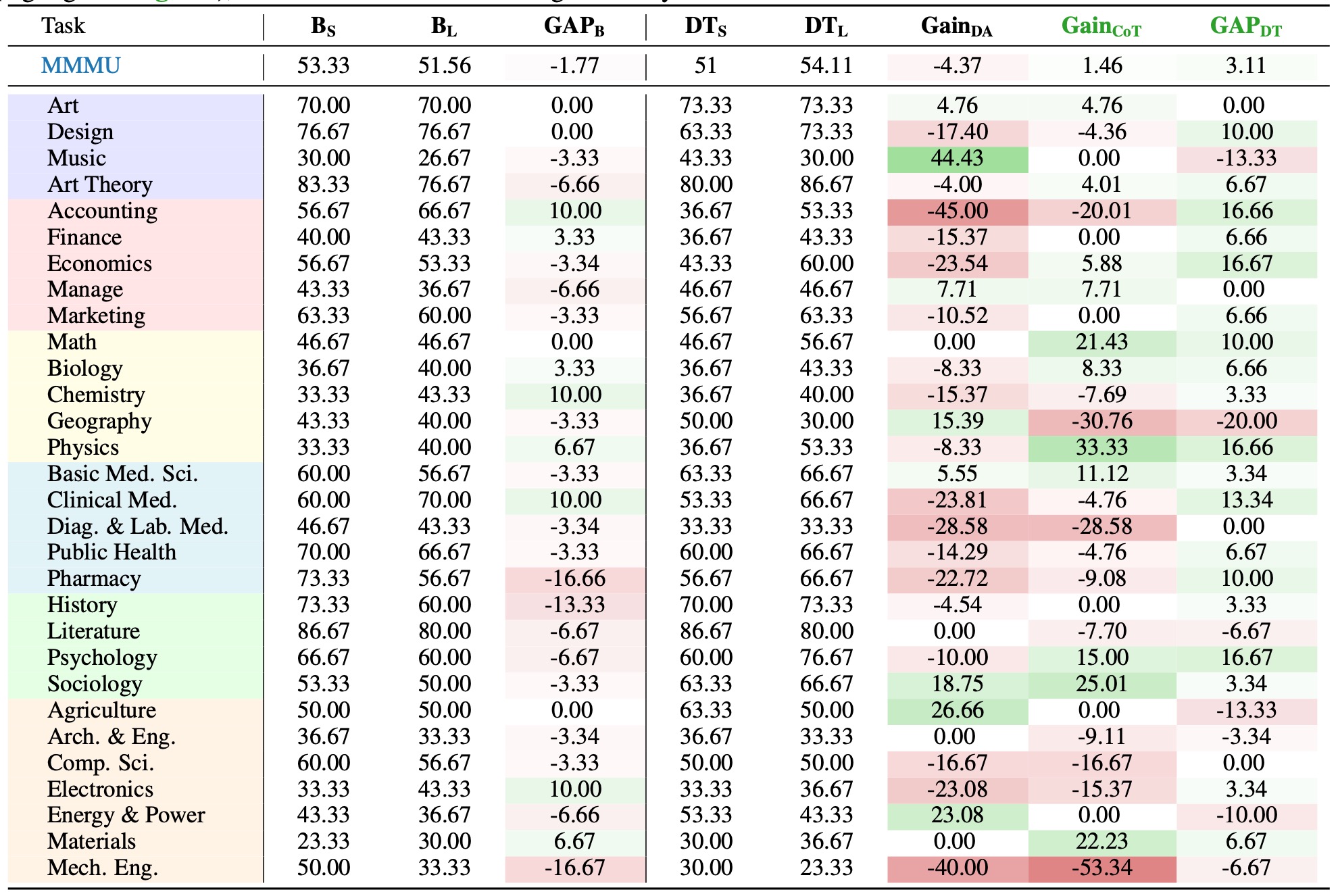
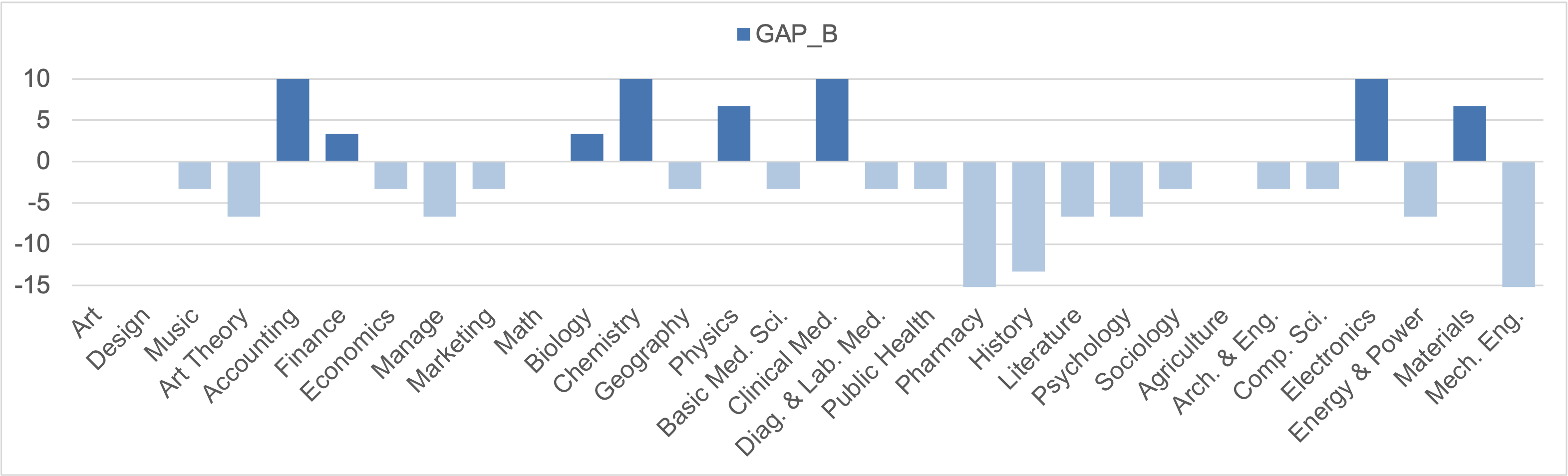
Figure 1: The base model shows discrepancies in initial performance between CoT and DA inference across various tasks. Positive values indicate that CoT inference has an advantage.
- ✅ In the multi-disciplinary domain, the base model exhibits substantial variation in performance across fine-grained tasks, as same as the suitability for reasoning training.
Further Exploration
Can RL Training Reverse the Reasoning Suitability?
Table 6: Performance Comparison Following Subsequent RL Training on Dual-Tuned Models for Spatial Tasks. Values in red and green denote negative and positive results, respectively. A task is identified as suitable for reasoning-oriented training only when both \( \mathbf{Gain_{CoT}} \) and \( \mathbf{GAP_{DT}} \) exhibit concurrent positive values (highlighted in green), which constitutes the Thinking Boundary.
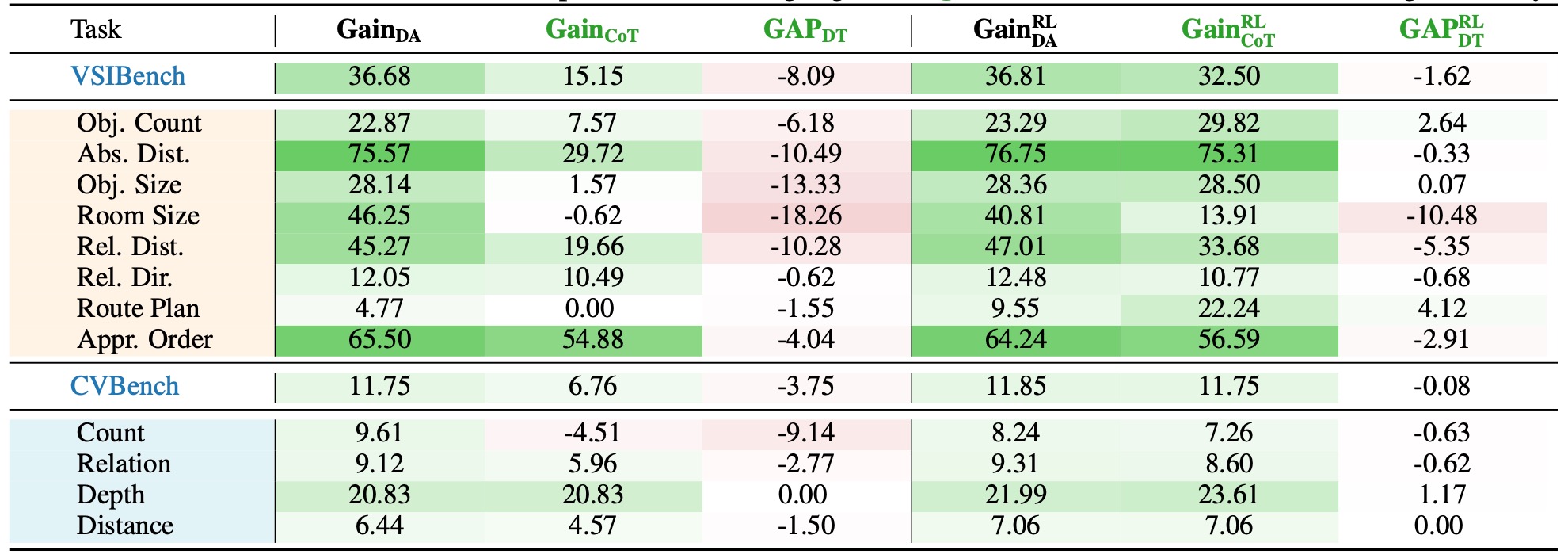
Table 7: Performance Comparison Following Subsequent RL Training on Dual-Tuned Models for MathVista Tasks. Values in red and green denote negative and positive results, respectively. A task is identified as suitable for reasoning-oriented training only when both \( \mathbf{Gain_{CoT}} \) and \( \mathbf{GAP_{DT}} \) exhibit concurrent positive values (highlighted in green), which constitutes the Thinking Boundary.
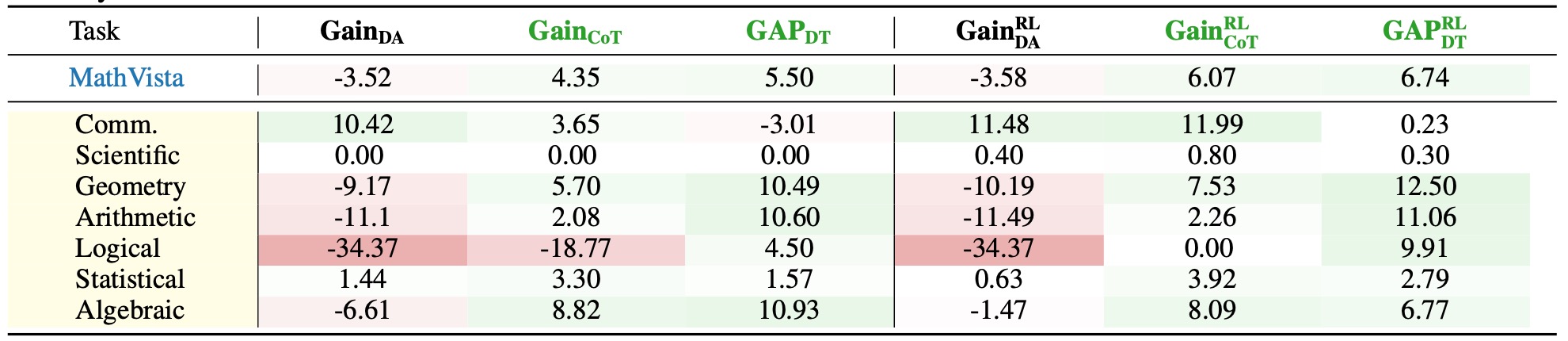
- ✅ Additional RL training does not alter the conclusions from Dual Tuning.
The Influence of Thinking Patterns
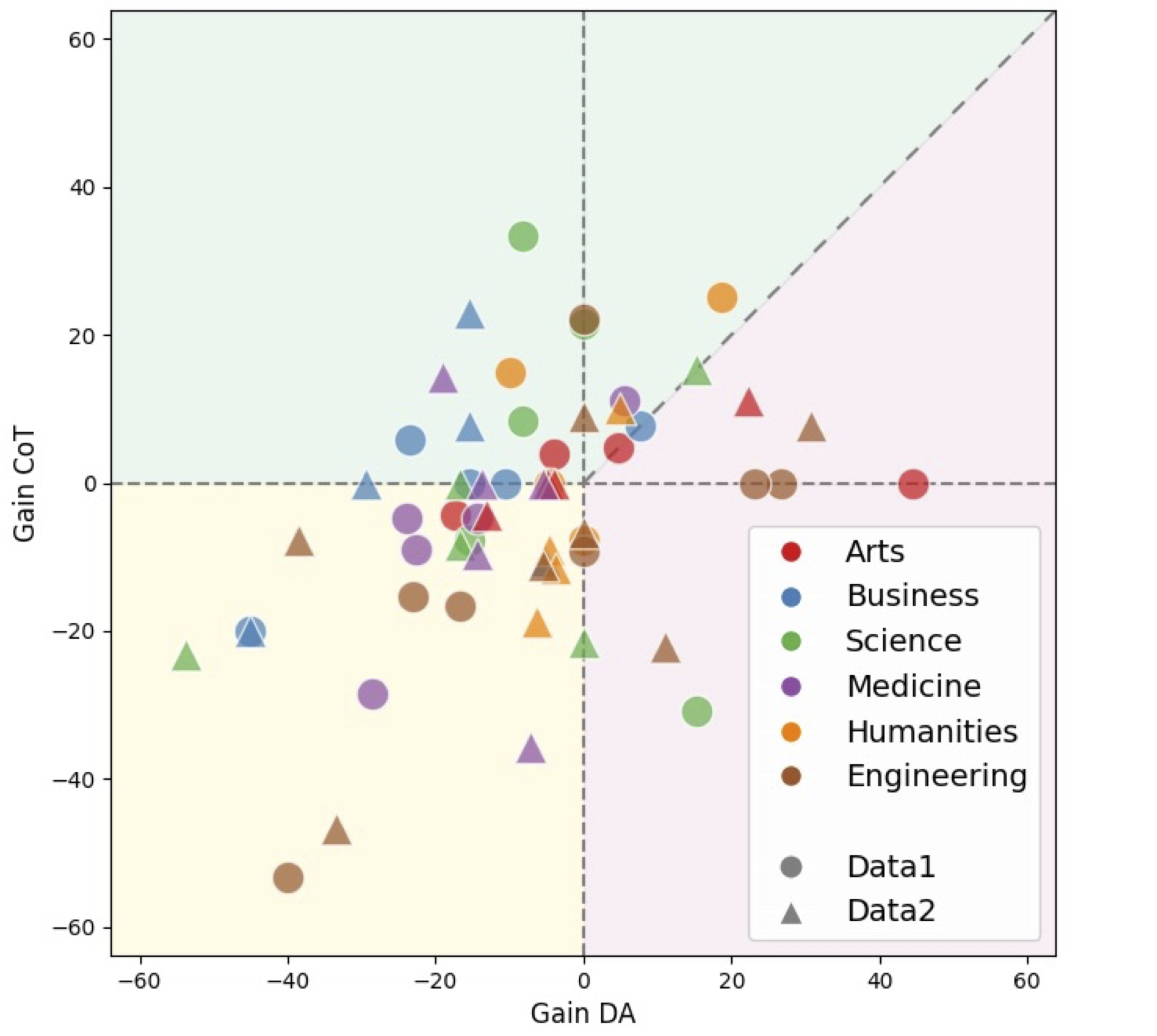
Figure 2: We evaluated on two different datasets, marked by circles (original) and triangles (new) on MMMU. The resulting change in task distribution highlights how Thinking Patterns dictate reasoning suitability across different tasks.
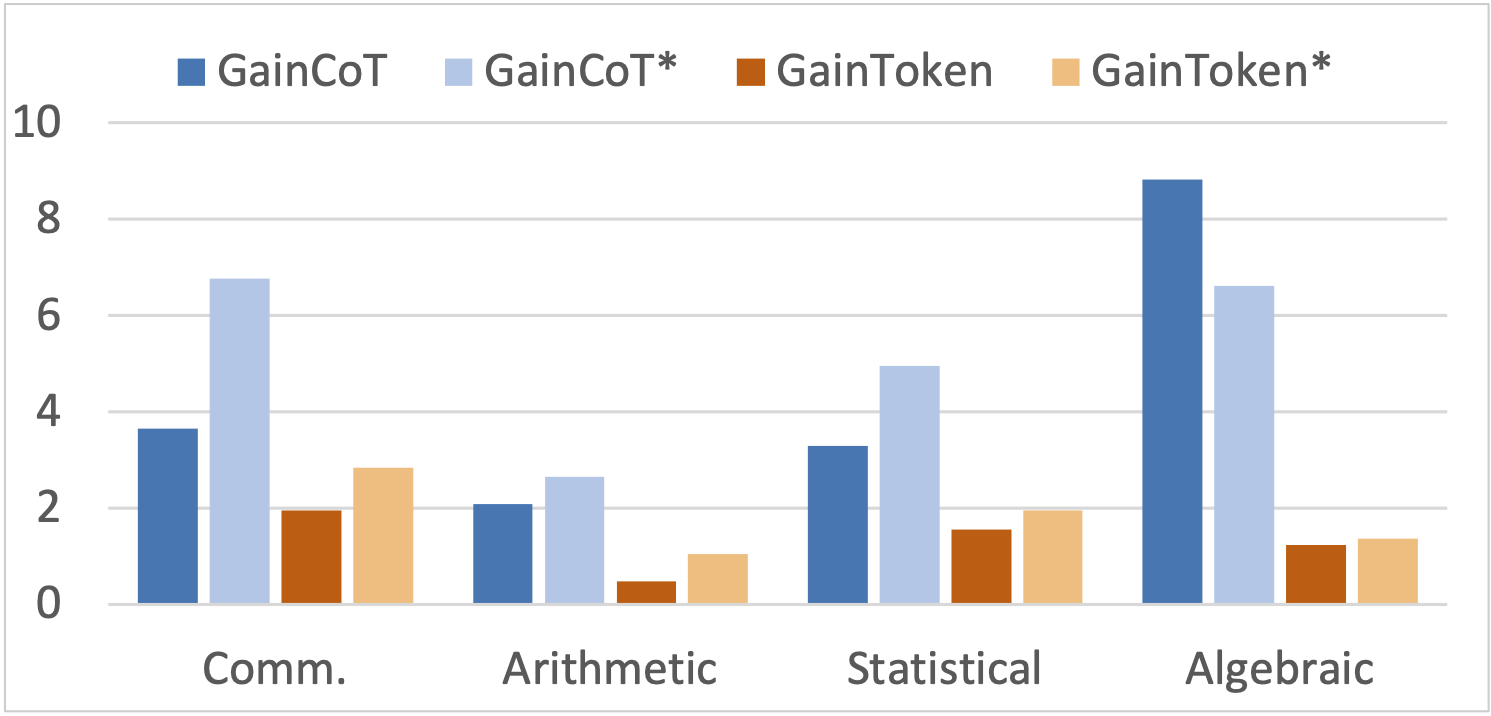
Figure 3: The effectiveness of a thinking pattern depends on its refinement and the exclusion of redundant or invalid reasoning. We compare the \( \mathbf{Gain_{token}} \) for both datasets on MathVista tasks.
- ✅ The thinking patterns embedded in different datasets influence training gains across different tasks and also affect token-level gains.
Can the Thinking Boundary Guide Data Refinement?
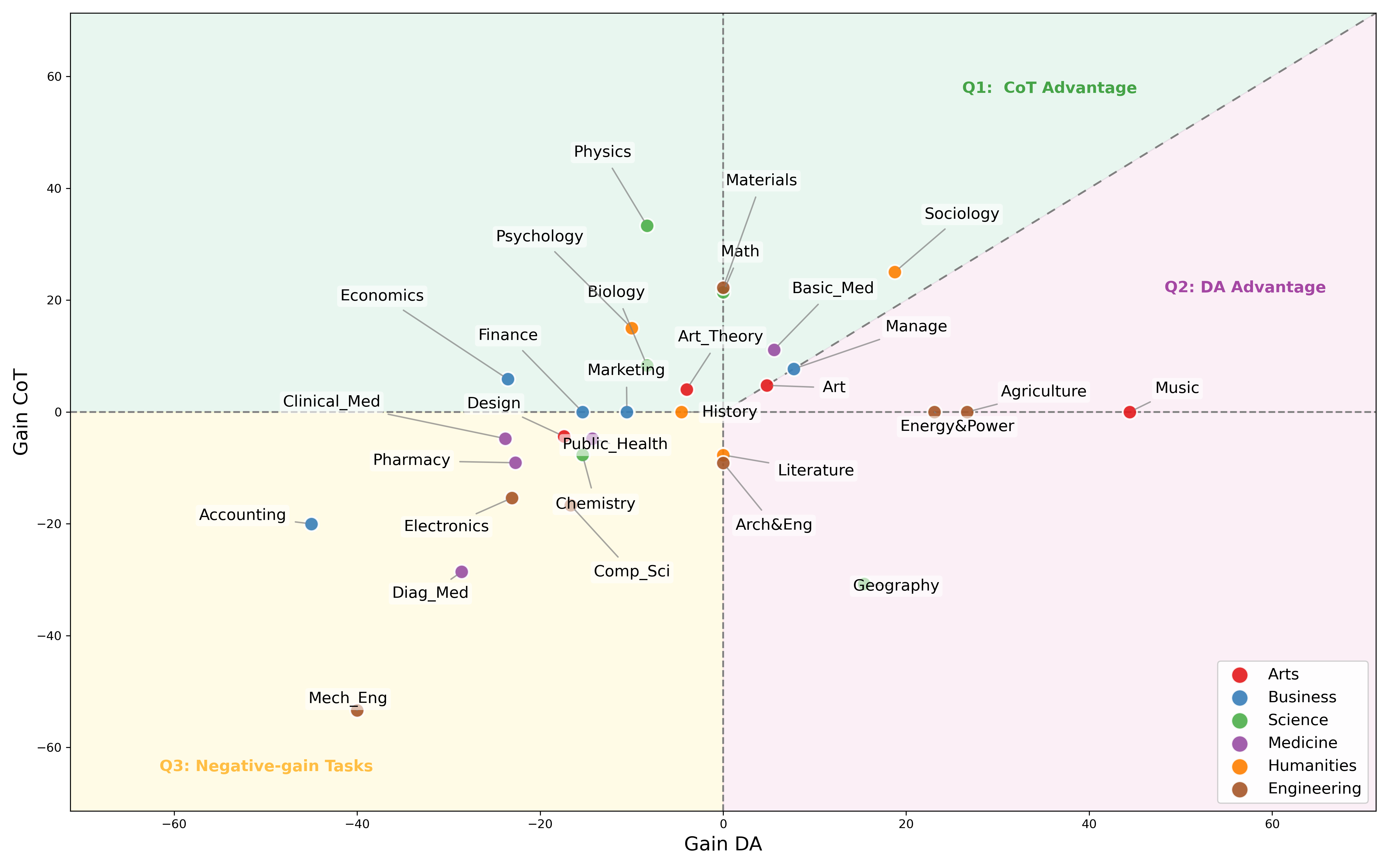
Figure 4: We plot each task's \( \mathbf{Gain_{CoT}} \) and \( \mathbf{Gain_{DA}} \) in a two-dimensional coordinate map. Through three distinct regions, we categorize the suitability of different tasks for the two training modes.
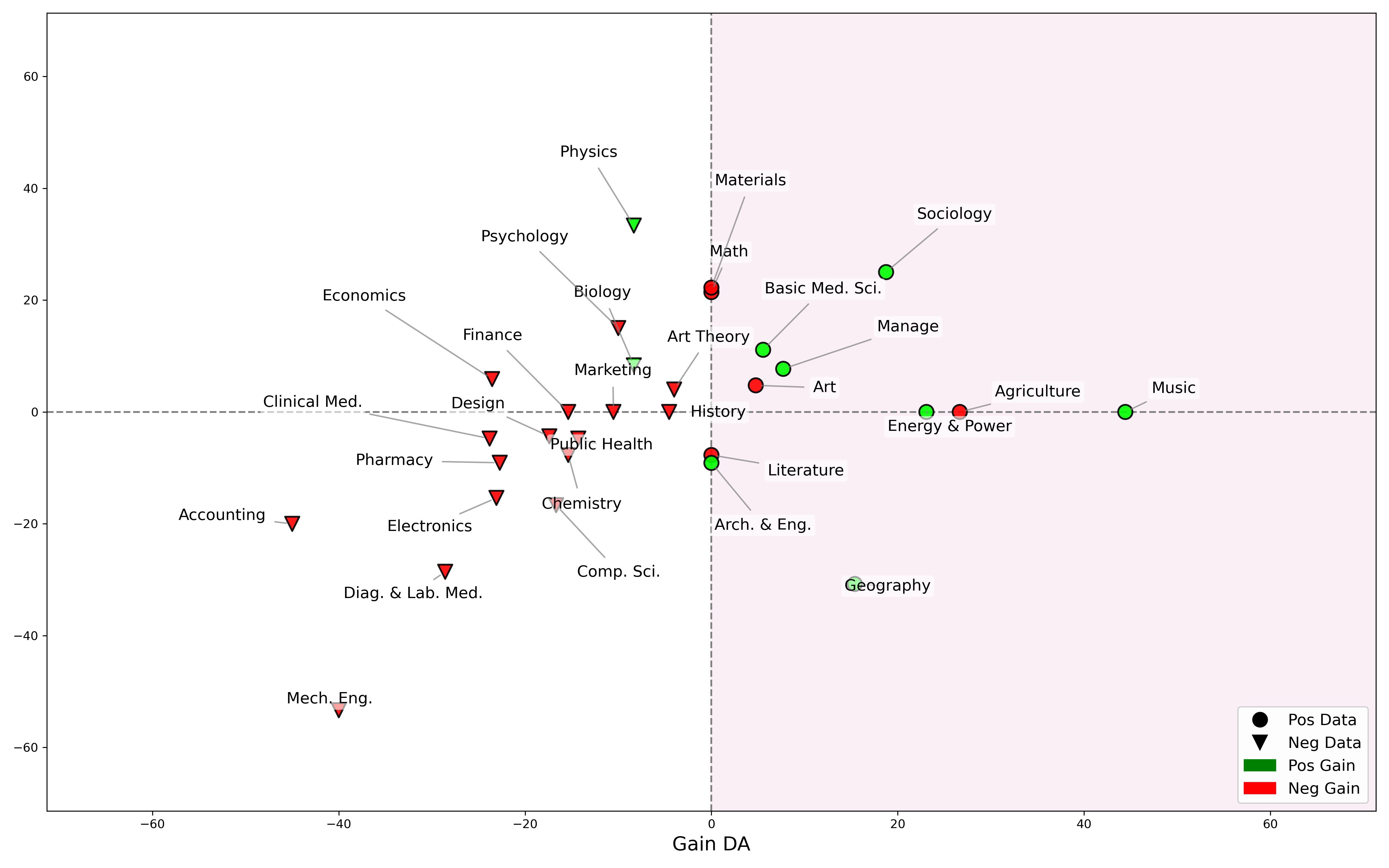
Figure 5: We partition tasks into two halves using \( \mathbf{Gain_{DA}} \) from Figure 4 and conduct two separate DA training on the data belonging to each half. The results show that left-side tasks predominantly show negative gains and right-side positive tasks mostly achieve positive gains after standalone training, which confirms the efficacy of the corresponding data.
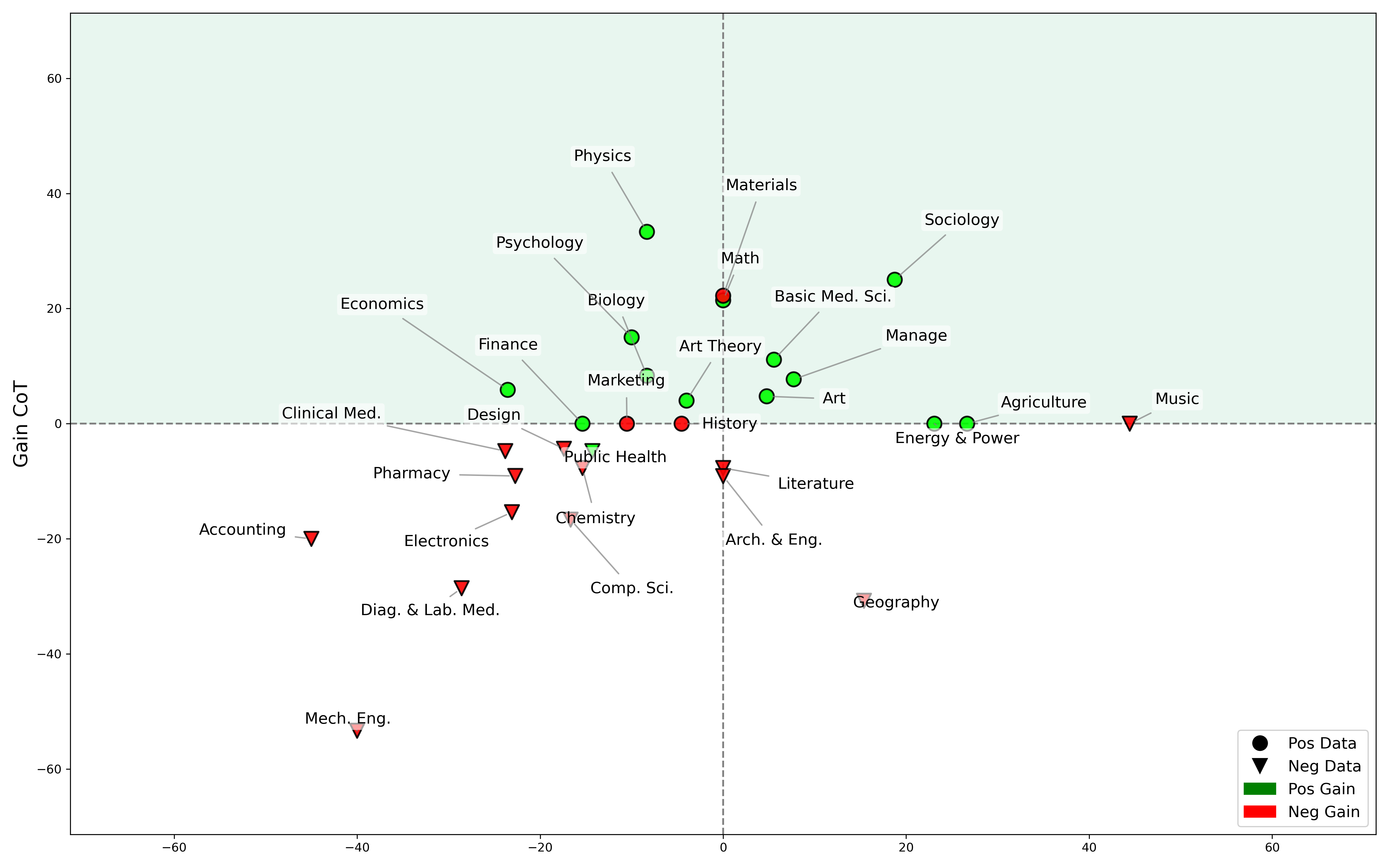
Figure 6: We partition tasks into two halves using \( \mathbf{Gain_{CoT}} \) from Figure 4 and conduct two separate CoT training on the data belonging to each half. The results show that the data corresponding to negative tasks (lower half) indeed yield negative gains during standalone training, and vice versa. These results confirm the efficacy of the corresponding data.
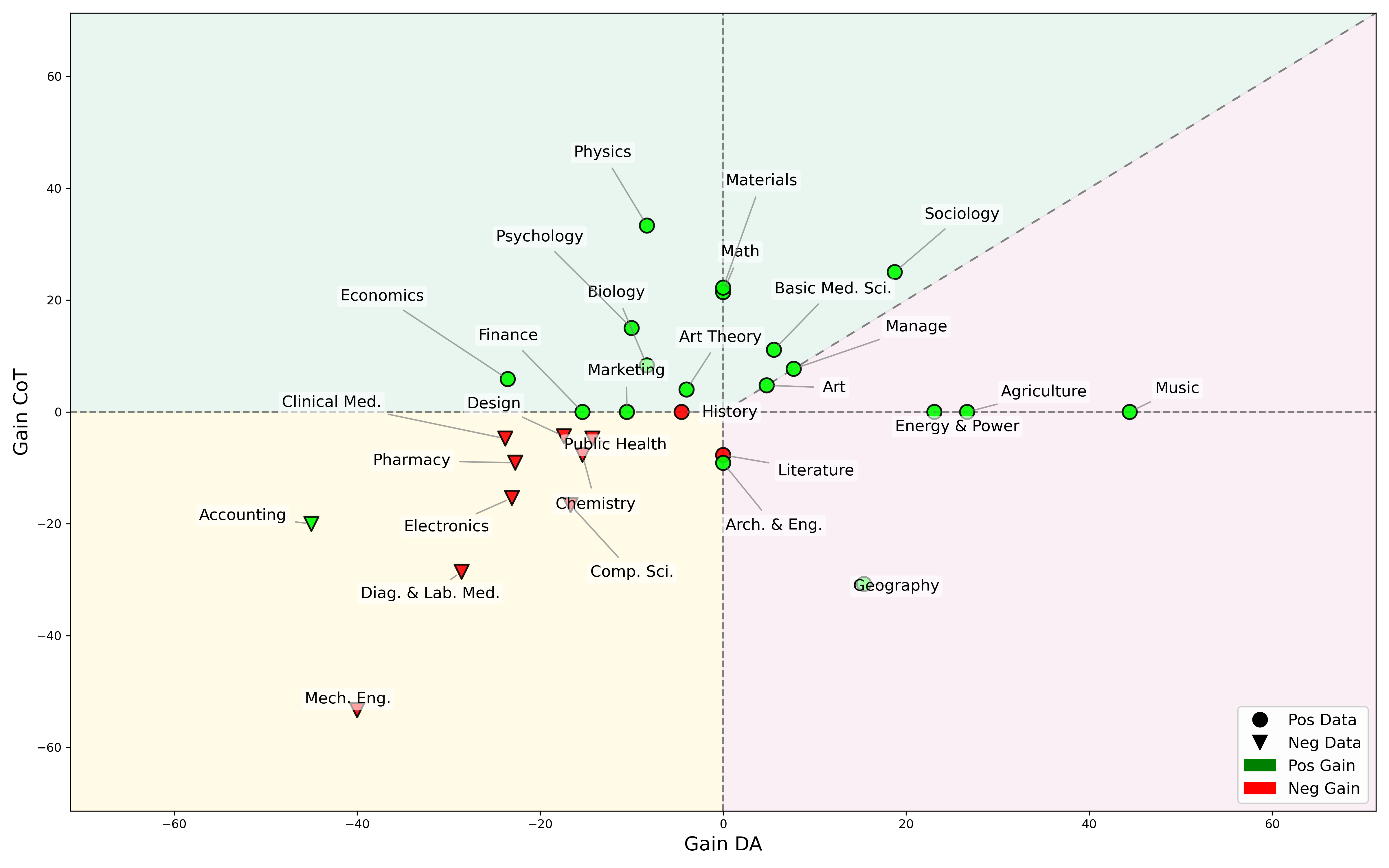
Figure 7: We separately train models with data from the lower-left negative region and the remaining three positive regions. For tasks in the lower-left yellow region, training solely on corresponding data predominantly yields negative gains. For the green and pink positive regions, training on the corresponding data reveals exclusively positive gains.
- ✅ This evidence confirms that Dual Tuning results capture the true efficacy of training data, offering actionable guidance for the identification and refinement of data subsets.